By J.R. WATKINSON
Error correction by interpolation works well enough on audio Compact Discs. But to exploit CD's potential for data storage, more precision is needed.
By storing digital audio in a highly durable medium convenient for mass duplication, the Compact Disc has overcome the major drawback of analog audio recording. Its tremendous success as a consumer product has brought down the cost of the player and made it attractive as a computer peripheral.
The Compact Disc is an optical disc which cannot be recorded by the user, since it is designed for mass duplication of pre-recorded music. It has many advantages as a storage medium. No contact is made between the disc and the laser pickup; and as there is no wear mechanism, life is indefinite. The principle of reading through the thickness of the disc reduces the effect of surface contamination. Random access to any part of the disc is easy because it is only necessary to move the pickup radially to reach any part of the recording.
CD's main advantage in a data storage application, however, is its capacity in relation to cost. Digital audio requires about one megabit per second per audio channel. Since CD can hold at least one hour of stereo, the capacity is staggering--about 600 mega bytes. This is the equivalent of about five reels of half-inch computer tape, or some 200,000 pages of text. A CD player costs about the same as the floppy disc drive in a home computer, but has about 1500 times the capacity.
Publishing houses are therefore exploiting the use of Compact Disc as a read-only memory--hence the name CD-rom. Technical databases are already being made avail able for commercial, financial and medical use. Several years' issues of all the major journals in a given discipline can be carried on a single disc, making optical disc publishing a reality. For companies, the cost of a suitable computer and CD-rom drive is trivial, and the cost of the discs is reasonable considering the storage space which is re leased. For the consumer, encyclopedias are a natural application.

---------Fig.1. A simple Reed-Solomon code over GF(8). At (a) two check
symbols and five data symbols of three bits each form a code word. The
code word will satisfy the equations of (b) if P and Q are correctly computed.
If at (c) there has been an error, symbol D becomes D', and the syndrome
So becomes the difference between what D should be and what it was. Syndrome
Si becomes the same quantity, but multiplied by a to some power. When the
correct power is used, equation (d) is satisfied, and the power of a becomes
the position of the error.
ADAPTATION FOR DATA
Compared to the heads used in magnetic disc drives, the laser pickup of a CD player is much heavier. Access speeds will therefore be slower than for hard discs, although similar to the speed of floppy disc drives. The track spacing of only 1.6 micrometers means that the destination track has to be approached slowly.
Unlike magnetic discs, CD uses a continuous spiral track. Once the beginning of a file has been located, the transfer of contiguous blocks can be completed without a seek. The spiral track and constant linear velocity principle of CD means that there is no such thing as the physical cylinder address which magnetic discs use to locate data. Data on CD-rom is addressed as a function of time along the track. If the pickup is at a given place on the disc and a different physical address is given, the time difference is easily computed; but this does not readily translate to a number of tracks to skip. As the track speed is constant, a track skip near the edge of the disc will cause a larger time jump than a track skip near the center. The number of tracks to be skipped can be estimated from the starting radius.
During a seek, the tracking error becomes approximately sinusoidal and it is an easy matter to count the cycles in the same way as a servo surface magnetic disc decrements the cylinder difference during a seek.
However, since the number of tracks to skip is approximate, it is necessary to read the actual address arrived at and to compute a short correction seek to reach the correct place.
In magnetic discs, data be comes scattered all over the disc surface as files of different sizes are erased and written. With CD-rom, a different approach is required. CD-rom cannot erase or record, and so the disc format never changes. To minimize the number of seeks necessary, it is essential to order the data into physically contiguous files be fore the disc is mastered.
A further problem is the error rate of Compact Disc. This is perfectly adequate for audio applications: on the rare occasion that an audio sample is not correctable, the previous and next samples can be averaged to conceal the error. This works in audio because there is a degree of redundancy in the signal.
For storage of computer data, interpolation cannot be used, since the average of two instructions is meaningless. The error rate of the normal CD must be reduced for CD-rom applications. This is achieved by adding an extra layer of error correction on top of the existing error correction system of CD.
ERROR CORRECTION
Two basic error mechanisms are at work in CD. Small random irregularities in the ends of the bumps where the disc is stamped can cause one 14-channel bit pattern to become another, corrupting eight data bits. Finger prints on the disc surface can make the track less distinct and large debris can obscure it, causing errors of many bits known as burst errors.
All error correction techniques work by adding to the data extra bits which have been calculated from the data. These extra bits convey no more information than is already contained in the data, and so they are said to be redundant. The addition of redundancy produces a data block which always has some special characteristic irrespective of the actual data content. In error correction, a block having such a characteristic is called a code word. If on replay the data block does not have the special characteristic, it is not a code word and there has been an error.
The redundancy added to the data is calculated mathematically from that data.
For simplicity of hardware implementation, the mathematics used is modulo-2, where there are no borrows or carries between different powers. In modulo-2, addition and subtraction mean the same thing. In a digital circuit operating with a finite number of bits, say eight, there can only be 256 different numbers, whereas conventional mathematics allows an infinite range.
In error correction, the more appropriate mathematics of finite fields is used because it makes the hardware simpler. Finite field mathematics was first developed by Evariste Galois (pronounced Galwah), so the term Galois Field is usually used. In a Galois Field, the finite number of states (known as elements) can all be obtained by raising the so called primitive element to successively higher powers. Whether two elements are added, subtracted, multiplied or one raised to the power of the other, the result can only be another element, which makes life very easy for the hardware designer.
In the Reed-Solomon codes used in the Compact Disc and in many other error correction systems, the principle of finite element fields is used exclusively. The size of the Galois Field is a function only of the number of bits in the data words used.
Compact Disc uses bytes, so that the field has 28 power elements, abbreviated to GF(256).
Every possible data byte is now an element of the Galois Field, or to be more precise, some power of the primitive element.
For the purpose of this explanation, a much smaller field, GF(8), will be used, because it keeps the examples to manageable size. The data symbols will be of three bits because 23 is eight. The principles of the Reed-Solomon codes remain the same what ever the size of the field. The number of symbols in a code word cannot exceed one less than the appropriate power of two, so in the examples there will be seven three-bit symbols.
The correcting power of a Reed-Solomon code is determined by the number of symbols in the code word that are allocated to redundancy. In Fig.1, two symbols are redundant, leaving five data symbols. The two redundant symbols P and Q are calculated so that the two checks shown will succeed if they are made on an error-free replay. The P check is simply a modulo-2 sum of all the symbols, and so if one symbol is wrong, the P check equation will give a non-zero syndrome So which will be the error pattern.
The P check cannot, however, decide where the error was.
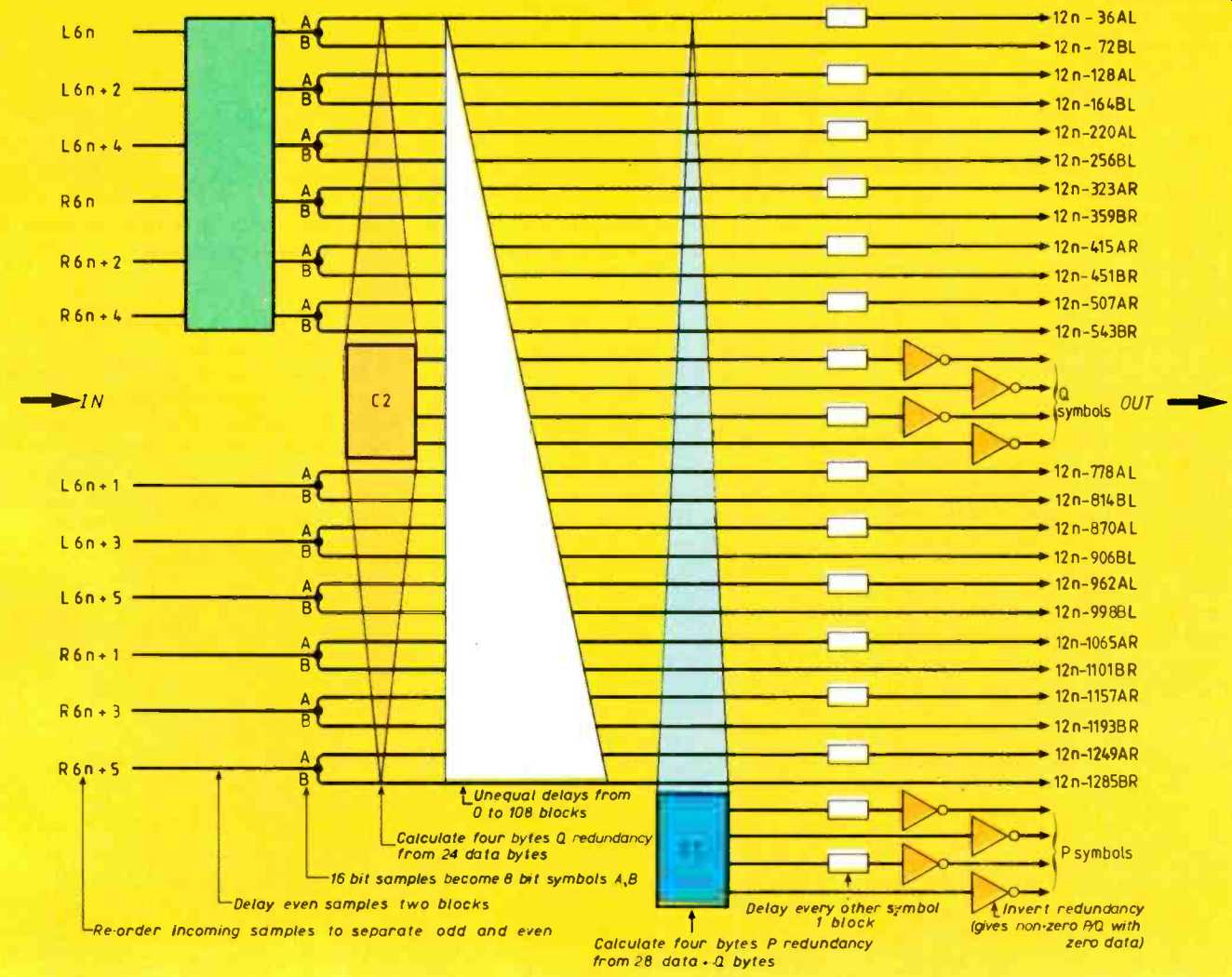
Fig.
2. The convolutional cross interleave of a normal Compact Disc. A random
error near a burst error can be corrected by the interleaved code word,
leaving the burst to be corrected after de-interleaving.
The Q check is subtly different because it multiplies each code word symbol by a different power of the primitive element. If one symbol is wrong, the syndrome of the Q check, S1, will be So which has been raised to a different power depending on the error position. If for example the middle symbol was wrong, the St syndrome would be the error pattern multiplied by the primitive element raised to the fourth power. It is only necessary to multiply So by ascending powers of the primitive element until the result is the same as S1, and the power needed gives the position of the error. In this manner, the Reed-Solomon codes can determine the nature of the error and its position. Adding So achieves the correction.
Effectively the system has solved two simultaneous equations to find the two solutions, which are the position and nature of the error.
There is an alternative mechanism which illustrates the power of the Reed-Solomon codes. If the position of an error symbol is already known by some separate means, then only one equation need be solved to find what the error is. Thus if the positions of two errors in the code word are known, then two redundant symbols are enough to correct them.
For example, if the fifth and sixth symbols are known to be wrong, the syndrome So will be the modulo-2 sum of both errors, whereas the syndrome SI will be the sum of the errors multiplied by the fifth and sixth powers of the primitive element. Solving these two equations will now give the two error terms known as correctors, which can be added to the offending symbols. The significance of this method will become clear when inter leaving is discussed.
If four redundancy symbols are used in each code word, then four simultaneous equations can be solved, with some difficulty, to locate and correct two erroneous symbols. But the complexity is considerable and there is some danger of miscorrection if the error is greater than two symbols.
INTERLEAVING
Using Reed-Solomon codes over GF(256) it is possible to correct errors of byte size, but much larger burst errors may occur because of contamination. The solution to these bursts is to use interleaving. Data is formed into code words, but these code words are not recorded one after the other on the track: they are woven together so that a large error causes slight damage to many code words instead of severe damage to one. In the convolutional interleave of Compact Disc, sequential sample bytes are formed into code words which become the columns of a rectangular array, which is then sheared by subjecting each row to a different delay.
The data bytes are again read out in columns, when they will have been interleaved.
If a burst error occurs, when the data is de-interleaved on replay there will be separate single symbol errors in several different code words, which can easily be corrected.
The problem with this simple system is that the occurrence of a random error near a burst can still result in excessive errors in one code word after de-interleave. The solution adopted is to use the so-called cross interleaving technique. In this approach, code words are formed on input data columns as before, but further code words are also formed on columns after interleave. A random error near a burst error is corrected by the interleaved code word, leaving the burst to be corrected after de-interleaving.
There is a further and powerful consequence of using cross interleaving. If a burst error occurs, the interleaved code will be overwhelmed and powerless to correct it, but it serves the purpose of detecting the error by declaring every sample in the code word to be bad by attaching a flag bit to them. After de-interleave, the burst error will have been converted to single errors in many code words, but with the significant advantage that the position of the error is already known. As before, if the position is known, twice as many errors can be corrected and so the de-interleaved code is made more powerful.
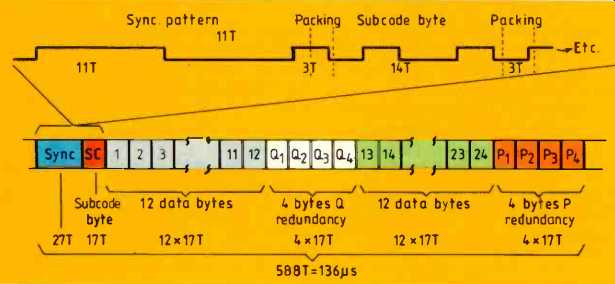
Fig. 3. One CD sync block begins with a unique sync pattern and one subcode
byte, followed by 24 data bytes and eight redundancy bytes. Note that each
byte requires 14 channel bit periods, with three packing bits between symbols.
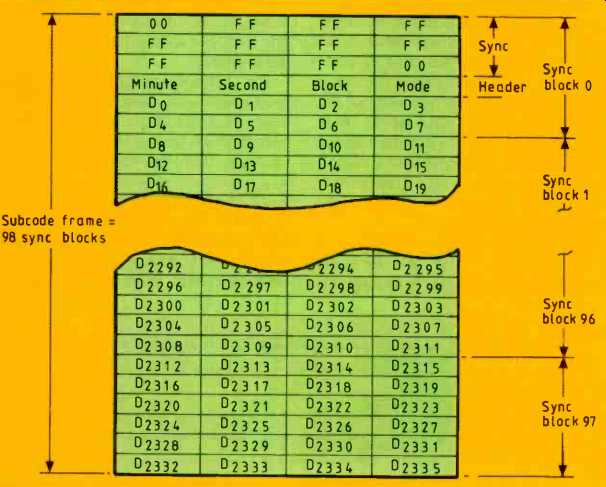
Fig. 4. Arrangement of CD-rom data corresponding to 98 sync blocks, or
one subcode block. There is a 12 byte sync pattern and a four-byte header,
leaving 2336 bytes for user data and redundancy.
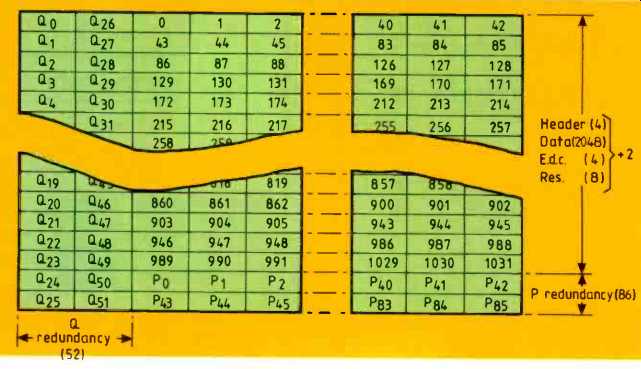
Fig. 5. The additional error correction of CD-rom. The P redundancy is
formed on columns of the array, whereas Q redundancy is diagonal, as shown
in Fig.6.
Figure 2 shows the interleaving arrangement used on the Compact Disc. Prior to interleaving, four bytes of redundancy Q are included in each codeword; and after inter leaving, another four bytes of redundancy P are included in the resultant diagonal code-
words. On replay, the four P check symbols will be used to correct random single byte errors with high reliability since all four equations must agree on the correction. The probability of making a miscorrection is very slight here. The presence of random errors is thus prevented from reducing the efficiency of the interleave.
In the case of a burst error. the P code is overwhelmed and attaches error flags to every symbol in the codeword, such that after de-interleave the four Q redundancy bytes can correct up to four errors. The way in which the two code words assist each other using the geometry of the interleave is What makes the cross-interleaved Reed Solomon code so powerful.
Under extreme circumstances the error correction system will be unable to correct properly. Suppose that after de-interleave, five or more error flags appeared in one code word. The correction system would have to declare all of the flagged symbols uncorrectable, and the only course of action available in a CD player is to use concealment. But in CD-rom this approach cannot be used.
Further error correction is necessary, which implies that more redundancy is needed.
CD-ROM BLOCK STRUCTURE
The sync block structure of the CD track is shown in Fig. 3. This is maintained in CD-rom so that the mastering equipment and playback processing can be identical.
Following the sync pattern, there is a single byte of subcode, then a total of 24 data bytes and eight redundancy bytes. The subcode bytes in a CD build up into a subcode block after 98 such sync blocks. This apparently strange number was chosen so that with the standard sampling rate of 44.1kHz the sub code block rate would be 75Hz. The subcode contains flags which assist the player to find the beginning of a particular recording. In CD-rom, the same subcode structure must be retained and so the data corresponding to the audio samples for one subcode block is made into one codeword block for error correction and addressing purposes.
One block contains 98 x 24 = 2352 bytes.
The structure of this block is shown in Fig. 4 in a way which relates to the original audio application of stereo samples of 16 bit word length. At the beginning is a sync field, which is all ones except for the first and last bytes which are zero. The next four bytes specify the time along the track from the beginning in minutes, seconds and subcode blocks (1-15) and the mode.
The track timing would normally be the same as the track timing carried in the Q subcode, but repeating it in the data field means that the player does not need to communicate subcode to the computer. A further convenience is that computer tapes generated for disc cutting have a time reference, since Q subcode is put on by the disc cutter.
Next there follow 2048 bytes (2K) of user data, which is a convenient size in computer terms. The remaining 288 bytes are occupied by additional redundancy and eight bytes reserved for future use.
It is now possible to deduce the actual user data capacity of CD-rom. Playing time is restricted to one hour, which brings a reduction in the raw random error rate by virtue of longer recorded wavelengths than for the audio disc (for which the maximum is 75 minutes). Since the subcode block rate is 75Hz, it is easy to obtain the user data rate as 2K x 75 bytes per second, or 150Kbyte/s.
The overall capacity of the disc is then given by multiplying this rate by the playing time:
60 x 60 x 150Kbyte= 540Mbyte.
EXTRA ERROR CORRECTION
The additional error correction needed by CD-rom also uses Reed-Solomon coding over GF(256) which means that the symbols are byte size. Figure 5 shows how the data corresponding to the subcode period is arranged. The 16-bit words from the CD are split into high byte and low byte and formed into two separate arrays which are identical in size and structure.
Each array is 43 columns wide. The first 24 rows contain the four-byte header, the 2Kbytes of user data and four-byte cyclic redundancy check character calculated over the header and user data. This serves as a final error detection stage after all the correction processes, to give a reliable indication that the corrected data is error free.
Each column of the array is then made into a P code word by the addition of two bytes of Reed-Solomon redundancy. The P redundancy occupies another two rows of the array.
Fig.6. In the block-completed cross interleave of CD-rom's additional error correction, diagonal Q code words wrap around so that 26 of them cover all of the block's contents.
To give a cross interleaved structure, Q code words are then generated on diagonals through the array. Figure 6 shows how these diagonals wrap around the array to form what is known as a block completed inter leave. As one diagonal begins in each row of the data and P redundancy, there are 26 diagonal code words. The two bytes of Reed-Solomon redundancy for each code-word occupy the first 26 positions of the last two rows of the array.
2048+ 4+ 4+ 8+ 172+104= 2340 data hdr e.d.c. res P q total
The action of the system is as follows.
When the disc is played, random errors are corrected before de-interleave and burst errors are detected. The error flags accompany the data through the de-interleave process to act as flags for correction by erasure. Up to four erasure corrections can be made by the standard CD player chip set, but if this number is exceeded the player declares them uncorrectable and in an audio application would use concealment. In CD rom, however, the second layer of error correction operates on the residual errors.
Each of the additional codes can locate and correct single errors, but erasure correction can double this power if the uncorrectable flags from the CD player are used. These are not always available, however. The block completed cross interleave of the additional correction system has as its input errors which are random, since the interleave of the CD player broke up all but the largest burst errors on the disc track. In some systems the additional error correction is performed in software, and this allows an interactive process to be used where P and Q codewords are used alternately to maximize the probability of correction. Finally the c.r.c.c. is tested, and if this is satisfactory, the data is assumed error-free.
SOFTWARE
The CD-rom standard specifies only how user data shall be stored reliably on disc and so each individual organization is free to use any directory structure under any convenient operating system. This is not necessarily a good thing, because it means that there is no such item as a standard CD-rom.
A given disc will be accessible only by the software it was designed to work with. The penalty of premature software standardization is that applications of CD-rom which are still emerging might conflict with it.
One solution which has been proposed is for CD-ROMs to contain several versions of retrieval software as well as the actual data.
Each disc would carry a standard boot block, which would allow a computer to read the appropriate control software from the CD rom itself.
Since the capacity of CD-rom is so large, the performance of retrieval software is crucial. Data on the disc must be indexed such that keyword searches can be under taken in the shortest possible time. In a relational database on a magnetic disc, the location of the physical address of the required data will need a path through a decision will result in a seek to the next linked file. But CD-rom seeks quite slowly, and retrieval software based on magnetic discs would be clumsy. The high capacity of CD-rom can be used to enable fewer layers of decisions to be made, out of more possibilities.
An extensively-indexed database might require as much storage for the index as for the actual data. There is, of course, a tradeoff, as the index size can be reduced if slower access is acceptable.
John Watkinson, M.Sc., is senior technical support engineer and educational consultant with Ampex Great Britain Ltd.
(Adapted from: Wireless World magazine, Oct. 1987)
Also see:
Ultimate Guide to Digital Audio
= = = =