(source: Electronics World, Aug. 1964)

By EDGAR VILLCHUR Acoustic Research, Inc.
Is objective testing possible? Do some tests have reliability but no validity? Can a device measure well but sound bad? Here is the viewpoint of a speaker designer with examples in his own field.
THE problem of testing, which is so crucial to design work, is one that a good many engineers know less about than they should. In schools, the techniques of testing have for the most part been the concern of the social-science discipline. I first learned about the basic principles of testing-the difference between reliability and validity, and the use of controls-from courses in psychology, sociology, and statistics, not from engineering courses.
We will consider here natters which are more often discussed in classes of social science than of physical science, but they are matters that you should be masters of.
Objective Testing in Audio
Objective tests of reproducing equipment-for frequency response, distortion, transient response. etc.-have been criticized from two widely different points of view, one scientifically legitimate and the other scientifically childish. I will discuss the latter first to get it out of the way.
It is an accepted principle among some of the hi-fi writers who advise the public on the mysteries of sound reproduction that high-fidelity components, and particularly loudspeakers, cannot be tested objectively. The reasons given usually relate to hearing differences in different individuals, differences in room environment, and differences in taste.
If we think of a high-fidelity system as a new musical instrument, a creator rather than a reproducer of sound, these reasons have relevance. But if we consider that the function of a high-fidelity system is to recreate with maximum accuracy sound whose character has been determined previously, they are irrelevant.
Differences in individual hearing have no more to do with comparing a copy to its original than differences in vision affect the objective accuracy of a matching color sample. The same hearing aberrations come into play in listening to both the live and the reproduced sound, and they do not affect the process of matching.
Room environment profoundly affects the final acoustic output of a sound reproducing system; this simply means that the room is one lint: in the chain of reproduction. Compensation for the effects of room environment (other than power requirements) must be sought in the flexibility of controls, not in design idiosyncrasies of the reproducing equipment.
Taste may determine whether a listener prefers a Stradivari violin to a Guarneri, but it cannot affect the objective determination of the accuracy of reproduction of either. Taste can only be involved where a choice must be made between different kinds of inaccuracy, for example, a given amount Of distortion us restricted frequency response.
These experts often tip their hand by an interesting contradiction. Knowing that audio design laboratories have invested in elaborate and expensive test equipment, and suspecting that this amount of cold cash would not be spent for useless measuring devices, they hedge. Sometimes hi-fi writers state that while objective measurements cannot provide a basis for the evaluation of high-fidelity equipment, measurements do serve as a useful tool for the designer. It should be clear that any measurements that do not have precisely the significance denied by these writers are as useless to the designer as to the consumer.
A kind of scientific know-nothingism is all too common in the field of high-fidelity testing, and it is necessary to bring some order into this chaos. What is needed is an understanding of the basic principles of testing, and particularly the difference between reliability and validity. Most engineers understand the teen "reliability "; however, they are quite often not sufficiently familiar with the term "validity." Reliability The reliability of a test is an index of its accuracy, an index of the extent to which we can expect the test results to be repeatable.
Let us suppose that we have a device with two electrical terminals, that we put the prods of a meter across these terminals, and read 5.3.8 volts. The reading is the same the next day with a meter of another make, which conforms to the specifications that we have laid out. It is the same in a testing laboratory in Alaska. Apparently we have specified the conditions of this test sufficiently so that we can expect the same reading each time. We have a reliable test. Note that I can call it reliable before I know what meaning, if any, the test has.

-------- A live versus recorded concert with the Fine Arts Quartet at a
moment of changeover from live to reproduced sound.
Let me give you an example of an unreliable test of this same device. A low-impedance meter may affect the circuit that we are measuring, but we fail to mention this in our description of the test procedure. With a vacuum-tube voltmeter we measure 53.8 volts. Someone comes along with a low-impedance meter and he reads only 32.6 volts. He may conclude that the voltage across the terminals is erratic and cannot be depended on for anything, but his analysis is wrong. It is the test procedure that is unreliable.
Validity
Now we come to the real crux of the matter, validity. What does that 5:3.8 volts mean-is it good, bad, high, or low? Is this voltage an index of some quality of the device? The validity of a test is that key quality which tells us whether the test measures what it is designed to measure.
We say that a given test measurement is, or is not, a valid index of a given characteristic.
There are test techniques surrounded by all kinds of quantitative controls, techniques that give us beautiful, accurate results, but which do not give us the information that we think they do. They are reliable but invalid. It is such test techniques that have given rise to the legitimate criticism of objective audio testing to which I referred. Sometimes a device is described as measuring well but sounding bad. When this is so, it is obvious that someone has measured the wrong things, however accurately.
I can give you an example from my own field of specialization, loudspeakers. As in other components of a hi-fidelity reproducing system, the frequency response of a loudspeaker is of prime importance. We are concerned with how even the response is over the range, and we are also concerned with how great that range is compared to the audio spectrum.
Now it is generally accepted in the audio field that the way to measure the frequency response of a loudspeaker is to place the speaker in an anechoic environment, put a microphone in front of it, run a sweep signal into the loudspeaker, and measure the output of the microphone at different frequencies. About twenty years ago Standards were published by RETMA (now EIA) and the American Standards Association, introducing the controls necessary to make this speaker testing technique reliable. If these Standards are followed in testing a given loudspeaker, you will get the same curve without significant difference every time.
But this on-axis curve does not represent what it purports to represent loudspeaker frequency response. Two loudspeakers with almost identical curves made in this way may sound entirely different in terms of whether they are bright or dull, smooth or rough.
The output of an electronic amplifier appears across definite terminals. Whatever comes out of the amplifier will be sensed by test prods across the terminals, and complete information on the amplifier output can be provided through the prods.
The output of a loudspeaker, which is acoustical rather than electrical, appears in quite a different way. This output is thrown out into the room in all directions, and the frequency distribution of the energy radiated directly in front of the loudspeaker is not the sane as that of the energy radiated to the sides. It is also true that when we listen to a loudspeaker in a normally reverberant room we hear a combination of direct sound from the speaker and reverberant sound reflected from the walls, floor, and ceiling.
The major part of what we hear is due to the sound field created by the reflected sound.
Thus, we respond more to the integrated power output of all those pencil-rays of sound that are radiated in an infinite number of directions than to the pressure of a particular ray between the loudspeaker and our ears. Even if we sit directly in front of a loudspeaker, the frequency response that we are affected by is not represented by the on-axis response curve. The test microphone was in an anechoic environment and did not sense any off-axis reflected sound.
To know the frequency response of a loudspeaker as it relates to non-anechoic environments, then, we need to know how much total energy the loudspeaker will radiate at one frequency compared to another, and the shape of the response curves at various angles to the speaker axis. This information is contained in a family of curves of the response at different angles from the axis of the loudspeaker, from 0 to 90 degrees. If the horizontal and vertical dispersion are not the same, we need to know both.
I have said that two loudspeakers can have almost identical on-axis response curves and yet sound completely different. This can occur in two ways. The off-axis response of one may drop severely at high frequencies compared to the other, giving the former a much duller character; or the off-axis response of one may be much more ragged than the other, giving it a rougher quality. (See Figs. 1 and 2.) These differences between the two speakers would be apparent from any listening position, including one directly on-axis.
The conclusion that we must draw is that the test technique of measuring only the on-axis frequency response of a speaker is not a valid one. The single curve does not represent the frequency response of the speaker, let alone serve as an index of its quality. But the conclusion sometimes drawn is that objective measurements are therefore useless when it comes to high-fidelity loudspeakers.
If I now say that we must not rely on the on-axis response curve but take a family of curves at different angles, and then take distortion cure as frequency curves and tone-burst data (we (lo actually use this particular gamut of tests at my company), what proof do I have that these measurements give us meaningful information? We can't just invent tests in our heads and then apply them. There must be validation of test techniques.
If we wanted to develop tests for the evaluation of printing equipment designed to reproduce paintings, the method or validating a proposed test would be obvious. We would see whether our test predicted the degree of accuracy of the reproduction, and we would check the accuracy in a (Erect comparison between the reproduction and the original painting.
In 1936, New York's Museum of Modern Art staged a "high-fidelity" show, an exhibition of color reproductions of paintings. The original paintings and reproduction of the paintings were hung side by side on the walls of the Museum, the reproductions in exactly the same sizes and in matching frames. One judged the success of the reproduction by direct comparison with the original. One didn't look at the reproduction and say, "The color is too dull." If the color was accurate compared to the original, dull or no. then the reproduction was a good one. All of the psychological and perceptive variables that would normally be operative in evaluating reproductions were under control. The control was the presence of the original.
Similarly, the validation of test techniques for audio equipment lies in a showdown display--the reproduced sound compared directly to the original live sound. If a test technique predicts well the degree of similarity between the live and reproduced sound it is valid; if test results do not correlate well with the results of the comparison, however involved the quantitative controls of the test, it is invalid and useless.
Several companies in high-fidelity manufacturing, including my own, have staged or participated in what Nye call "livers recorded" concerts, in which live and reproduced sound are alternated. We have used a string quartet and a pipe organ, as has G. A. Briggs of Wharfedale, The validation of test techniques, or the evaluation of equipment directly, call then be made with guesswork reduced to a minimum.
These public concerts serve u dual function for us—they are part of a serious validating and evaluation program, and they are also part of an advertising program. In serving the former function the concerts have certain disadvantages. We can't have the Fine Arts Quartet travel to AR every time we want to test a design variation, or validate a new test technique, or compare a group of loudspeakers. There is also a human element involved--the musicians may not be playing exactly the same way during the test as they played to make the original tape. So we have worked out a technique in which we use this live cs recorded approach, but instead of a quartet we use a mechanical sound generator, and instead of music we use white noise (or a portion of the white noise speculum) as the live sound.
[1. The analogy to the reproduction of paintings is not perfect, since reproduced music k usually heard in a changed acoustical environment. but it does work. Accurate high-fidelity equipment can recreate musical timbres either raw or as they are molded by the concert hall. depending on the recording technique. If the character of these sounds is to be changed purposely for living-room listening. such a change will have to be brought about by composers and musicians, not by design engineers. ]
[2. Villchur. E.: "A Method of Testing Loudspeakers with Random Noise Input." Journal of the Audio Engineering Society. October 1062, Vol. 10. No. 4. pp. 3.:6-319. Reprints are available from Acoustic Research. Inc.. 24 Thorndike Street. Cambridge. Massachusetts. 02141. ]
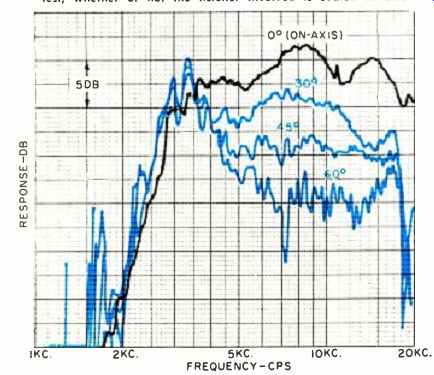
Fig. 1. Family of machine-run frequency-response curves on a commercial tweeter,
from on-axis to 60 off-axis. Based on on-axis curve alone, response could be
described as 3.5 db from 3 kc. to 20 kc., leading one to expect outstanding
performance. An examination of the off-axis curves, however, shows that total
power radiated is badly peaked at 3.2 kc. and high-frequency response is greatly
attenuated off-axis. It is the latter characteristic hat shows up in listening
test, whether or not the listener involved is seated on-axis.
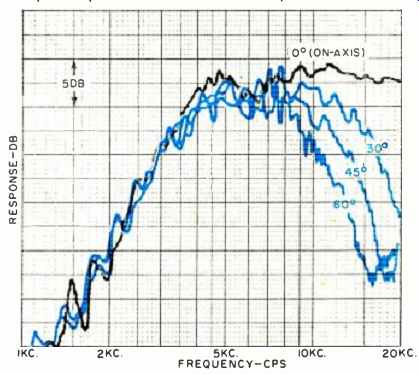
Fig. 2. Family of machine-run frequency-response curves on a super-tweeter,
from on-axis to 60 off-axis. As in Fig. 1, a reading of the on-axis curve alone
would give misleading information, since there is far less power radiated at
higher frequencies than this curve would suggest. While the off-axis curves
remain fairly smooth, there is clearly room for improvement in high-frequency
dispersion. At the present state of the art, however, author knows of few speakers
that will even equal the performance that is illustrated by the curves below.
You all know what white noise sounds like--if you have never heard a white noise generator you've heard of FM interference or hiss. It is neutral, without musical pitch. Any aberration or coloration in its reproduction is even more evident than in music, and so its use makes the test more sensitive.
Our reproduction of white noise has never been so close that it could rot he distinguished from the original, whereas we were able to reproduce a pipe organ or string quartet well enough so that most of the switchovers from live to reproduced sound would not be detected if one's back were turned.
We can make an anechoic recording of this white noise and then play it back, switching hack and forth between the original live white noise and the reproduced white noise. When we listen we pay no attention to whether we like the reproduced white noise or don't like it, whether it soothes us or jangled our nerves, whether we think it pleasant or unpleasant. We only consider whether it is similar to the original. The basic technique, instead of an A-B technique, is an A-B-C technique, where C is the live sound.
The standard A-B technique is like comparing the reproduction of a painting to another reproduction instead of to the painting itself. It is better that nothing, particularly if yon know the original painting, but an A-B choice lacks the control which will pin the matter down to that of reproducing accuracy.
Let us assume that we make a design variation in a speaker. We will designate the standard speaker as A, B the speaker with the design variation, and C the live reference. Then we switch C–A, C-B. It’s surprising how little listening time is required before we know whether the standard speaker A sounds more like the live C, in which case the design variation has failed, or the new design B sounds more like C, in which case we know that were going in the right direction.
The very subjectivity of the test reading eliminates those elements which are not significant to aural perception. The test is conducted in a normally reverberant room, so we respond to the complete frequency response of the speaker.
We use the technique both as a direct design and testing tool and as a validation technique. When the primary purpose of testing is to rank a group of reproducing devices in their order of excellence, the live vs. recorded display is useful for direct evaluation. When information about a single device is to be communicated, or where diagnostic information is required, the live CS recorded display serves as a validation of other test techniques rather than a test technique itself. After making these tests with both random noise and music., we find that the noise is an accurate stand-in for musical sound.
It should now be clear that the choice sometimes presented in methods of equipment evaluation--listening us objective testing--is a false one. Objective measuring techniques are useless unless they have been validated by subjective means, that is, by listening. Such listening must ultimately make a comparison with the original live sound, and a live us recorded display provides the basic' validating technique. Any meaningful listening to recorded material, of course, at least makes reference to a memory of the live sound, but this memory is necessarily imperfect, Once a test has been validated as an index of performance, it can reveal information that might take many hours or even clays of uncontrolled listening to discover.